JupyterLab is an awesome piece of technology for prototyping and self-documenting research. But can you use it for projects that have a big codebase ?
The case for an external library
The notebook workflow was a big improvement for all data scientist around the globe. The ability to directly see the result of each step and not running over an over the same program was a huge productivity boost. Moreover, the self-documenting capacity make it so easy to share to coworkers.
That said, there is a limit to what you can achieve in a notebook. It is best for interactive computing, but it’s no longer interactive when each cell is more than 100’s lines of code. At this point, what you need is a real IDE like VS Code or PyCharm and maybe some unit tests.
Being developed outside of your current project, a good library should be generic enough to help you, and your coworker, on a wide range of projects. See it as an investment that will pay back many times in the future.
Now, how can you push this library back into Jupyter?
The Python kernel
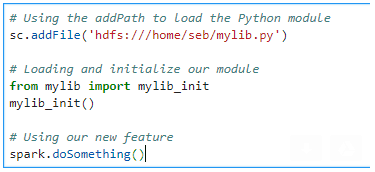
Suppose you want to add new functionalities to Spark objects, for instance a doSomething() method on Spark and a predict() method on a DataFrame. You create a module (a file in Python, so for instance mylib.py) with the following code :

The mylib_init() uses the setattr() function to expand the classes definition for SparkSession and DataFrame and add the new methods. All you have to do in your notebook is to create a code block with the two line below (block 4). First import the function “mylib_init()” definition, and then call it.
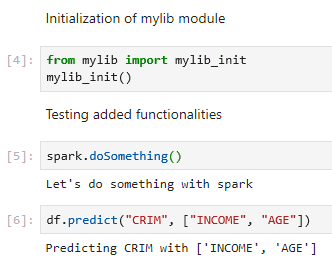
The minor issue is that if you change the mylib.py file, it will not change anything in the workbook even if you call mylib_init() again. I found out about the autoreload plugin in this post. This will allow Jupyter to check every 2 seconds for a new version of the .py. You just need to call mylib_init() to use the newer module.

So that was the easy case when you create the Spark driver inside your Jupyter instance using the pyspark library (for instance by using the code below).

That’s the easy way because all stay on the same computer. It’s a bit more complex (but not so hard) when things get remote, for instance when using Sparkmagic.
The Sparkmagic kernel (Python and Scala)
The Sparkmagic kernel allows your Jupyter instance to communicate with a Spark instance through Livy which is a REST server for Spark. Sparkmagic will send your code chunk as web request to a Livy server. Then, Livy will translate it to the Spark Driver and return results.
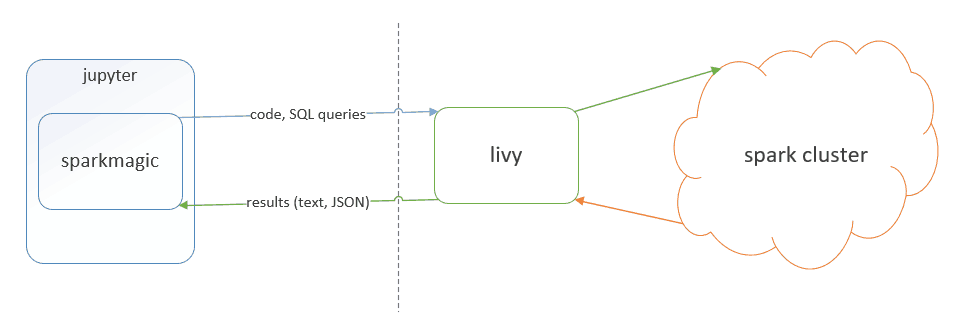
As you can see in the diagram below, the Spark driver is remote on the cluster and doesn’t have access at all to the file under the Jupyter instance.
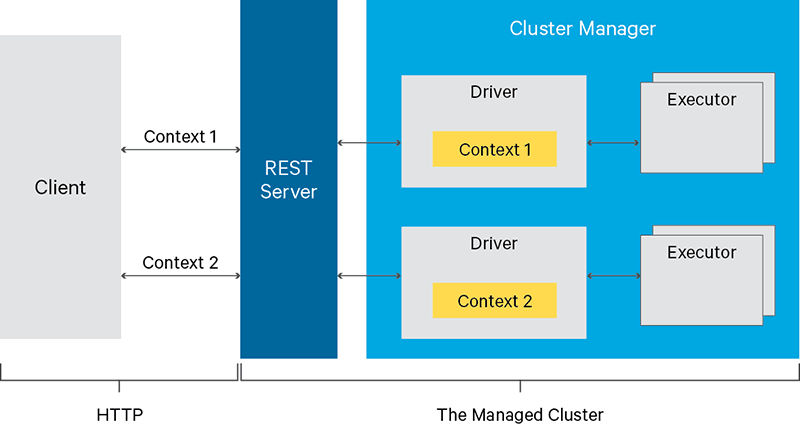
How can you solve this issue and use your library?
If you use Python, you can store your code on the underlying HDFS and use sc.addPath (sc being the SparkContext automatically created by Sparkmagic). As both the driver and the executors have access to HDFS, it will work.
For Scala, we want to be able to add one or more JAR file to the classpath. JAR are libraries in the Java ecosystem. Sadly, while there is a addJar on SparkContext, this way will not work. As Scala is compiled and typed, you can’t just add the JAR in a chunk of code and use the types from this JAR at once. addJar will make this possible for the executors, but for the driver it is no longer possible to add class definitions when addJar is called.
Luckily, there is a way to inform Livy which JAR to add to the classpath when it creates the SparkContext (before any code is sent to be compiled).

Notice that this block will restart a context if there is already one, so it should likely be the first block of your notebook. You should also keep existing configuration parameters (use %%info to get your Livy configuration).
The best of both worlds
As we have seen, whichever your situation, there is a way to leverage an existing codebase and keep only high-level meaningful code in the Jupyter Notebook.
I strongly feel that the key to a high performance data science team is to always invest time in productivity increasing tools. A shared library of high-level primitives is paramount to productivity. Jupyter works fine with that and that’s good news.
Let's stay in touch with the newsletter

Leave a Reply
You must be logged in to post a comment.