Kind of a rant discussing the shift of Data Science towards technology and losing sight of the business value. With ideas to think outside of engineering.
There is currently a trend in Data Science to converge toward software engineering. I’ve seen it recently in a Toward Data Science podcast with Adam Waksman from Foursquare (very interesting podcast). As he said, Foursquare Data Science team is focused towards the product. They work on the product, making production code. The analytics team was integrated inside product over time. Therefore, it’s becoming an engineering function.

While Adam keep the support function Business Intelligence separated, the trend is to merge it with software engineering as well. Last time I check at my former employer Blizzard Entertainment, most Data jobs are now labeled Software Engineer (but you should apply nevertheless).

We need to think where it comes from, what it implies and if this is a good trend.
Let’s start with a bit of history.
Where does it come from?
Ten years ago, what was then called ETL/BI Developer was thought for people without the ability to become software engineers. After all, they needed a drag and drop UI because … well … they were lame programmers, right?
In fact, the reason for having a drag and drop UI was to be faster and focus more on the logic than the technology. And that was true. Working only with data, the number of operations is limited. You could see data flowing through every node of an ETL graph. It was a bit faster to code, easier to debug, and faster to understand. On the other hand, every time you hit a limitation, you were trapped. It was also very difficult to make high level primitives.
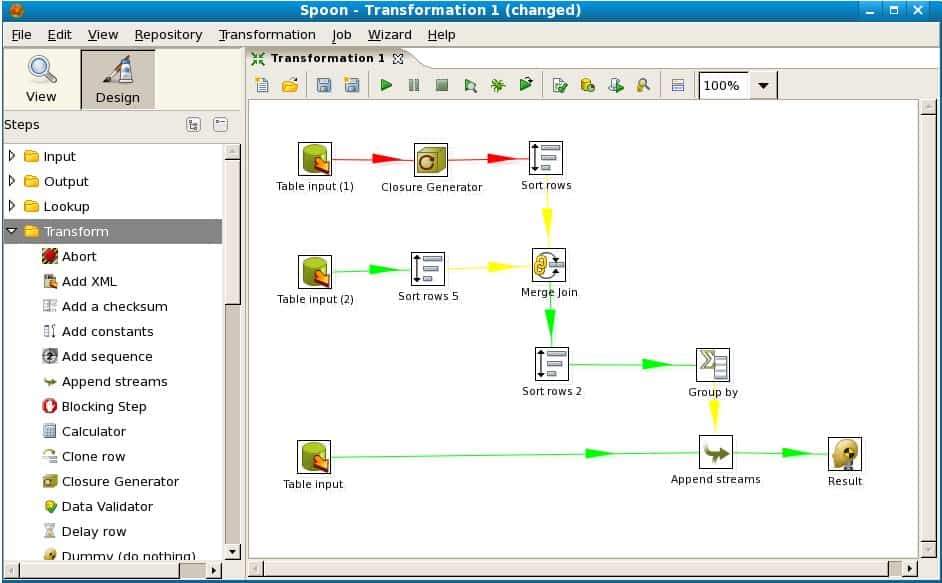
One thing that made those tools less relevant (they still exist) was the switch from ETL to ELT (loading data in the data warehouse then making transformations inside). While the ETL tools were computation engines, we learnt that nothing can beat a database for data processing. Indeed, how could it be smart to take data from the database (or data lake), transfer it to the ETL engine, process it (with a less powerful computation engine), then move it again to the database. Just too many bottlenecks.
Writing a SQL query is probably harder but it’s many orders of magnitude faster (to process and I would argue to write as well).
At the same time, the database movement was disrupted by newcomers like Hadoop. To make a data lake of it, you would be happy to write in Java or in Pig Latin. It was not very powerful, neither easy but it was cheap (at least at face value). To work with data, you had to be a software engineer. That, to me, set the foundation of blending data and software.
From the machine learning perspective, I don’t remember any good UI tool. The industry probably wasn’t big enough to set a real competition. SAS and SPSS led the place until R emerged. SAS and SPSS were so old school that anything could be better.
Fast forward, we now have Spark and Jupyter powered by Python both of which are improvements over the Hadoop ecosystem or the machine learning of the time. By its scripting nature, Python gained more and more ground. You might now use Python everywhere (that’s great!). The most recent example is the raise of Apache Airflow for ETL. Nothing bad on the surface, but you know where the devil hides.
Is Python devil?
I would argue that Python paved the way of seeing data jobs more from a software perspective. On the surface it makes a lot of sense. Python is easy to write and supported by an amazing ecosystem. Whatever you might want to do, there is an easy library for that (processing, visualization, machine learning, …). Python is even production ready (many websites are run with Python). Python came from software development (Java and Scala too but their influence is limited).
It just make sense to import good devops practices from software engineering like versioning, CI/CD, Kubernetes, … can you have too much of a good things?
I argue that yes, we are focusing too much on software.
Back to the Airflow case, reading the tutorial page at the time, you have a nice big Python script with a Do not worry if this looks complicated for introduction. Notice as nowhere on the page the objective of the script is given.
Not that the issue is Airflow by itself. I’m guilty as well when I write:
At this point, what you need is a real IDE like VS Code or PyCharm and maybe some unit tests.
JupyterLab for complex Python and Scala Spark projects – DataIntoResult.com
Speaking of Spark, knowing where the code is executed (on Jupyter, on the driver, on the executor) is a serious issue for beginners that require a good understanding of distributed computing. Such knowledge was not needed for decades old MPP databases.
Everything is becoming about software development. The complexity is increasing and require more mind bandwidth. Are we missing something here?
Business vs data vs software
For me, Data Science at a company is about solving business issues with data, not technology and not software.
You might define Data Science as the application of statistical and mathematical methods to decision-making problems. Does it make sense for you? Interestingly, that’s the original definition of IT (Information Technology) as defined by Harold Leavitt and Thomas Whisler in this HBR article from 1958. I would argue that Technology took precedence over Information.
The objective of Business Intelligence is almost the same.
I feel there is a shift from Business Intelligence to Data Science to Software Engineering. At each step, we remove ourselves with what really matter, the business. It is easy to fight over a technology like PowerBI vs Tableau or Python vs Scala. The picture below comes from the talk “How To Set Up A Data Team” by Sam Cohen, Operations Director at YOPA. Just after setting a team he had to mediate a dispute over tools. How does that help the business?

I’ve been in such debate many times. I never saw a debate about time allocation between marketing and finance (in which domain is Data Science the more effective?). Which product should we spent time on? Whatever debate that reckon that we are paid to bring value, not playing with toys.
At Blizzard, I started working on Starcraft 2. It was the new kid in town. Shortly after, I saw through the data that Starcraft 2, despite being my favorite game, wasn’t big enough to really move the business needle (yeah, Blizzard standards are insanely high). I limited my time to some half-baked, ugly Cognos reports (hard to do anything else with Cognos anyway) and devoted much of my time to World of Warcraft.
We are in a unique situation where we have access to most data and the ability to process it and generate insight. That need tools, but that’s not the main part.
Why fancy machine learning will not save you
Do you remember the Netflix Prize? 1M$ offered to the best machine learning algorithm that could beat Netflix own algorithm by 10% on predicting video ranking. Thousands of data scientists around the globe (myself included obviously) worked on it. 3 year after the beginning the BellKor’s Pragmatic Chaos team won.
Was the model used? Nope.
The solution was too complex to be used. It was an ensemble learning of ensemble learning. BellKor’s Pragmatic Chaos is the blend of at least 4 teams algorithms (wisdom of the crowd, since then, Random Forest is my one-trick pony).
Did the problem even matter? Nope.
In fact, video ranking isn’t useful at all. As related in Wired, ranking is not used much nowadays. What you say you like is not what you really like. All those years and computer cycles were just wasted.

Therefore, what should we do if it’s not train a Random Forest backed by Spark versioned under git in a Docker container? I don’t have a definitive answer on that, but I think we should focus less on tools and more on the business. Some wording like Data Detectives.
Why we should be more data detectives
We are in 2020, becoming a Data Scientist is just a Coursera click away. Python is so easy that a kid can write production code. Moreover, there is millions of software engineer that can learn Data Science in a whimp. Is that the best we can become? Commoditized?
I don’t want to. What is the new frontier?
What if the new frontier would be our ability to solve unseen problems? Our embedded rationality and our thirst for data are giving us an hedge for that.
Sounds Sherlock Holmes? Maybe we need to be Data Detectives.

Let me introduce two idea we can focus on to become better data detectives.
Embracing the business
Remember, Data Science is about solving business issues with data. The most important decision is not choosing between a neural network or SVM. It’s about which problem to tackle. Which problem can be solved with data and can impact the business the most?
In order to find an answer, you need to understand deeply the business model of the company, its main metrics and the internal politics.
Do you know the revenues and profit margins of your company? Does that seems important to you?
Thinking outside the model
While the ensemble learning approach didn’t help in the Netflix Prize (I mean beside gaining $1M), it is really effective for humans. At least, that’s what Charlie Munger, the Warren Buffett partner, thinks:
Developing the habit of mastering the multiple models which underlie reality is the best thing you can do.
Charlie Munger
There is a great course on Coursera about Model Thinking. It’s especially fun as we related to some models from machine learning. But it’s not technical at all.
For instance, I used my learnings about economics to model the monetary market dashboard of the Diablo 3 Auction House (now discontinued).
Notice as well that deep learning came from neuroscience. Getting idea from unexpected places can help.
You might disagree with this article. In fact, I know that I will go back discussing engineering in my next articles. Just after finishing this writing, I will test some concepts in Python. We are engineer at heart.
But I still feel that’s not the best use of our core competencies.
Do you?
Let's stay in touch with the newsletter

Leave a Reply
You must be logged in to post a comment.