Today, I turn 37, and I feel the day is great to launch my first product, Data Brewery. It’s an open-source ETL for data warehouse with an emphasis on agility and productivity.

Why another ETL product? A bit of history
The current consensus is to use Pentaho Data Integration (PDI). At the time of writing, the open-source version is downloaded 25 000 times per month. I have used it for 10 years. I remember when I arrived at Blizzard Entertainment finding an existing PDI ETL. At the time I was more leaning towards Talend and I had used Business Object a lot (now SAP). The first one (Talend) was way to verbose on metadata. The second one (Business Object) was just outdated (no copy/paste for instance).
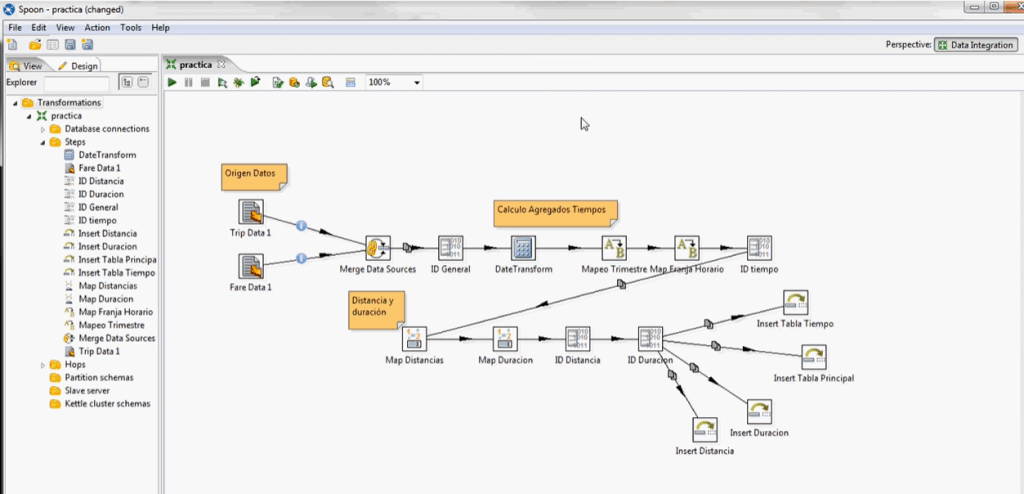
Soon enough I hit PDI limits, building a framework around it (environment management, testing framework, …). As the complexity grew, it became more and more complex to manage (with thousands of jobs and steps). The ETL world was also shifting from ETL to ELT and most of the work was done with SQL queries. The next step was logical, I built a PDI project generator because it was no longer efficient to express it in PDI.
The tool took a XML file and produced all needed PDI files (which are XML as well).
Now, Data Brewery, is only a step further, the XML specification is almost the same, but the PDI underlying is removed.
On the need of a higher level framework
With a tool like PDI, you can express anything but it’s not easy to factorize. For instance, you might want to track the time taken by each SQL query in a database. Either you add steps around every SQL query (impossible) or you parse the log file (painful). But even then, you still need to figure the best way to store the data.
The same goes for testing your processes (good powerpoint here which show that it’s definitely not easy) or managing errors. PDI doesn’t enforce anything but doesn’t provide much neither.
On the contrary, with a higher level framework, more decision are already made on how to handle some situation and come out of the box. You end up being more productive.
Obviously, you might disagree with some decision embedded in the higher-level framework. Data Brewery makes some decision which makes it super-efficient in some situations at the expense of not being for everyone.
My assumptions
I wrote an ETL – Data Warehouse manifesto to express my views on how it should be done. Let me summarize a bit:
Module-based
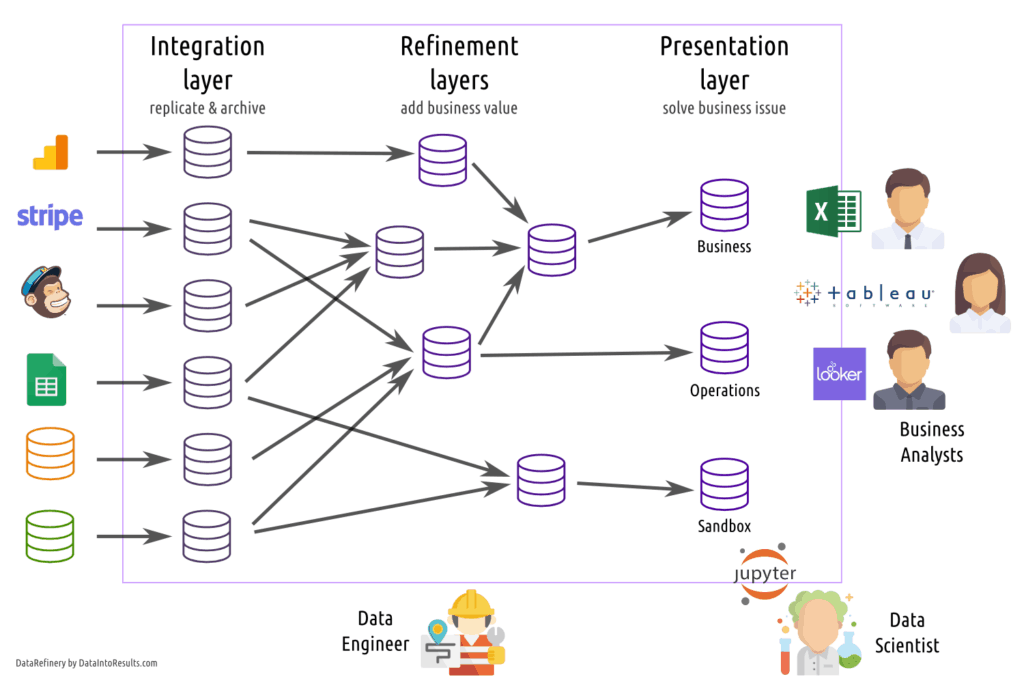
I view the data warehouse as a set of modules. Each one has a specific purpose and are divided in 3 layers: integration, refinement and presentation. Not a good fit if you want to use the Data Vault philosophy.
Strongly ELT
I really believe that almost everything should be done inside the data warehouse with SQL. Do you love SQL ? You should.
Agility
I put a strong emphasis on agility. A new business rule should be implemented in less than a day. Therefore, refinement and presentation layers are rebuild from scratch by default.
Durability
A byproduct of the module framework is that each module can have a different quality of service. You can upgrade/rewrite your data warehouse module by module.
Cost-efficiency
It is designed to increase the developer productivity. I love delivering value and looking for insight. Writing ETL pipeline is a need not a goal. If there is a trade-off between developer time and computer time, I always favor the developer.
The road ahead
Data Brewery is already used in production by some of my clients but I, obviously, have an infinite list of feature to add (testing framework, Spark integration, …).
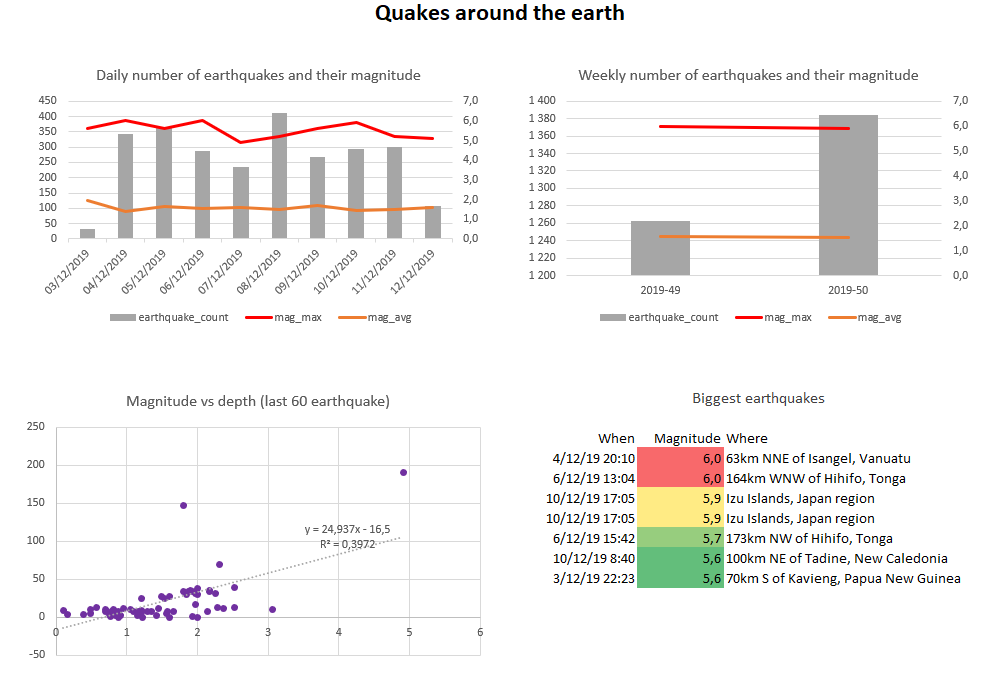
Want to know more about Data Brewery? I encourage you to test it with a tutorial on earthquake data and let me know of you like it (or not) and if something stand in the way to succeed with it. I promise to respond to every feedback (mail me at seb _@_ databrewery.co).
Happy ETL.
Let's stay in touch with the newsletter
