
After analyzing the pro and cons of PostgreSQL for data science, I thought it was fair to do the same for MySQL and its fork MariaDB. According to Coursera, you can manage Big Data with MySQL. Is MySQL or MariaDB suited for the analytics workload of data science? Can it be used as a data warehouse? Last time I looked into MySQL was teen years ago. What has changed since then? Let’s dive in.
Pro: Rich SQL
Ten years ago, the SQL support from MySQL was clearly subpart. Since then, a lot of progress was made. Most needed elements are supported including :
- Common table expressions : fully supported since MySQL 8.0 and MariaDB 1.2.2. That’s a deal breaker to write big queries.
- Windows functions : Fully supported for both databases.
- Unstructured data handling :Both MySQL and MariaDB support JSON as a native type and offer many function. Basic XML support is available as well.
Pro : Multiple storage engines
One thing I loved about MySQL was that it comes with many storage engine options. While InnoDB is the default choice, you can use the ARCHIVE engine which store data in a compressed format. As you can see on the graphs below, it takes a lot less space (15% of the InnoDB space) and it is 3 times faster to run a query on it.
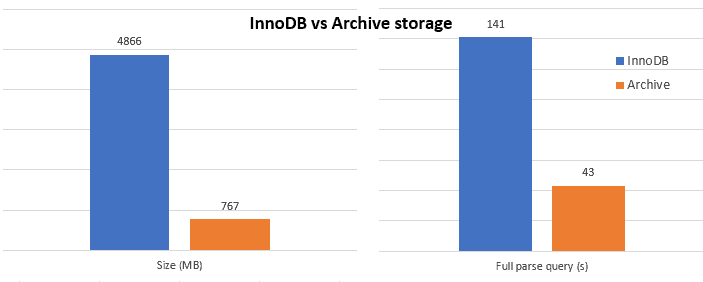
You might wonder why operating on compressed data is faster. After all, you need to uncompress data on each read which is expensive (and the zip format used is not the best speed wise). But, even with SSD, the bottleneck is disk speed and not computing power.
Pro: Partitioning
Data partitioning is fully supported. All types of partitioning are supported like RANGE, LIST, HASH and KEY.
Using partitioning can speed up greatly your queries. For instance, if you are querying the previous year of data, having partitioned your data by year discard all the previous years (which can be a 10x speedup if you have 10 years of data).
I should note that partition pruning didn’t work on hash partitioning for year(date).
Cons : No hash join (MySQL only)
One area where no progress has been made for MySQL is the join strategies. It only has one : the nested loop join (and some variations of it). While it works perfectly for small joins (joining few rows regarding the table size) it doesn’t work at all for analytical queries (where you often join more than 10% of a table). In such queries, you really want to use the hash join strategy : the smaller table is loaded in a hashmap first giving you a constant access time to any row. Sure, creating the hashmap is expensive but the rest of the join is blazing fast.
MariaDB has a hash join strategy in it but it’s disabled by default. To enable it, you should set the configuration join_cache_level to 8.
MariaDB [test]> show variables like 'join_cache_level'; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | join_cache_level | 8 | +------------------+-------+
Cons : No query parallelism
With analytics queries, we usually run a few big SQL queries and the ability of a database to use many cores to run each queries is very important. MySQL or MariaDB can use only one core per query and keep the others idle.
There might be a way using SPIDER storage engine, but I haven’t dig into that.
Cons : Limited bulk data loading
While there is a fast bulk data loading command with LOAD DATA INFILE (works for a file at the server or at the client), it is somewhat limited. For instance, it is not easy to ingest a compressed csv file let alone anything more complex (like a stream to avoid having a file).
Nevertheless, if you are on a Linux computer, you can create a FIFO pipe like below:
mkfifo --mode=0666 /tmp/customer gzip --stdout -d customer.csv.gz > /tmp/customer
And then use the load command inside a mysql client
load data infile '/tmp/customer' into table customer columns terminated by ',';
In conclusion
While good progress has been made, especially on SQL compatibility, it’s still hard to advice MySQL or MariaDB for a data science setup or a data warehouse. While I didn’t disclose all tests here, it was always way faster in a out of the box PostgreSQL.
That said, there is a column store engine in MariaDB (taken from InfiniDB). I didn’t test it here because it is not a real engine but more a different product. Nevertheless, we can expect that it will be perfectly suited to analytics.
Let's stay in touch with the newsletter

Leave a Reply
You must be logged in to post a comment.