
I’m playing with Apache Spark seriously for about a year now and it’s a wonderful piece of software. Nevertheless, while the Java motto is “Write once, run anywhere” it doesn’t really apply to Apache Spark which depend on adding an executable winutils.exe to run on Windows (learn more here).
That feel a bit odd but it’s fine … until you need to run it on a system where adding a .exe will provoke an unsustainable delay (many months) for security reasons (time to have political leverage for a security team to probe the code).
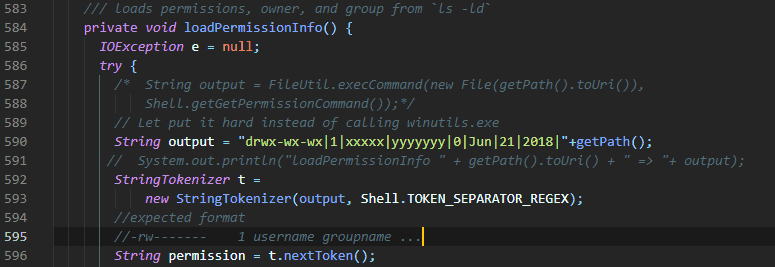
Obviously, I’m obsessed with results and not so much with issues. Everything is open source so the solution just laid in front of me : hacking Hadoop. An hour later the problem was fixed. Not cleanly by many standard, but fixed.
The fix
I made a Github repo with a seed for a Spark / Scala program. You can find here. Basically I just override 3 files from hadoop :
- org.apache.hadoop.fs.RawLocalFileSystem
- org.apache.hadoop.security.Groups
- org.apache.hadoop.util.Shell
The modifications themselves are quite minimal. I basically avoid locating or calling winutils.exe and return a dummy value when needed.
In order to avoid useless message in your console log you can disable logging for some Hadoop classes by adding those lines below in you log4j.properties (or whatever you are using for log management) like it’s done in the seed program.
# Hadoop complaining we don't have winutils.exe log4j.logger.org.apache.hadoop.util.Shell=OFF log4j.logger.org.apache.hadoop.security.UserGroupInformation=ERROR
While I might have missed some use cases, I tested the fix with Hive and Thrift and everything worked well. It is based on hadoop 2.6.5 which is currently used by Spark 2.4.0 package on mvnrepository.
Is it safe?
That’s all nice and well but doesn’t winutils.exe fulfill an important role, especially as we are touching something inside a package called security?
Indeed, we are basically bypassing most of the right management at the filesystem level by removing winutils.exe. That wouldn’t be a great idea for a big Spark cluster with many users. But in most case, if you are running Spark on Windows it’s just for an analyst or a small team which share the same rights. As all the input data for Spark is stored in CSV files in my case, there is no point of having an higher security in Spark.
I hope the tips can help some of you.
Let's stay in touch with the newsletter
